AI/ML Architectures Mythology
Apr 05, 2023
Describing different options for building AI/ML Architectures for flexible business environments in mythological terms...
Contents and TLDR
| Pipeline Abstraction Name | Description |
|---|---|
| The Persephone Protocol | The most basic pipeline abstration with no detail. |
| The Daedalus Dataflow | Exploding the basic pipeline chart into some additional data science tasks. |
| The Prometheus Pipeline | Adding some specific data cleaning or scheduling functionality. |
| The Zeus Zonal | Adding Jupyter Notebook. |
| Nemesis Normalization | Model Selection and Storage. |
| Odysseus Orchestration | Keeping Track of Models, Dealing with Exponentially Difficult Debugging. |
| Epimetheus Endpoint | Deployment. |
| Hephaestus Hold | Feature Storage. |
| Kubeflow Kraken | Full Service Pipeline Workflow. |
Introduction
Framing Mythological Nicknames for AI/ML Pipeline Construction
The launch of ChatGPT has demonstrated the immense potential of Large Language Models, making it impossible for business leaders to ignore the importance of Machine Learning and Artificial Intelligence. While sales, marketing and product development conversations can be dynamic and fluid, at the end of the day, developers must create code that works, compiling into results that can be displayed on screens.
However, the fast-paced nature of today’s business world means that companies may not have a clear idea of their ML/AI needs or the investment required. To overcome this challenge, developers must not only understand how to architect and build an ML platform but also stay up to date on the latest open-source tools.
To help facilitate planning and conversations about what is needed at what time, the author has put together this guide using mythologically-inspired nicknames to help explore several different iterations of what a basic ML platform architecture looks like and provide insight into how developers can balance the need for cutting-edge technology with just getting stuff done within a timeframe.
In the world of Greek mythology, the launch of ChatGPT may have been seen as a display of immense potential, not unlike the power wielded by the gods themselves. Just as the craftsmen of the ancient world had to master the use of new tools and techniques to trade and do battle with newly discovered civilizations, so must engineers of today strive to build the best possible solution for our companys’ and organizations’ unique needs. While it’s tempting to aim for godlike power and build a Ferrari, sometimes all we need is a humble chariot. As developers, our objective should always be to spec-out the minimum amount of software needed to achieve a business goal. But that doesn’t mean we should compromise on quality. We must take pride in building the best possible chariot, with the flexibility to adapt and evolve as needed, much like Hercules had to balance his divine duties with their mortal concerns.
The Persephone Protocol
So that being said, let’s take a look at the most basic, abstract look at what a machine learning platform does.
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> preprocess -> train -> evaluate -> deploy;
}
In this simple abstraction, the processing and model training stages represent the time the Ancient Greek God Persephone spent in the underworld, and the evaluation and deployment stages represent the return to the world above.
With any machine learning platform of any kind these steps always exist in some form or another. In perhaps in the most basaic possible development configuration, these steps could be held in a collection of different folders, and the deployment could literally just be a button press of some kind to invoke a pre-built model. Let’s look at these steps to start off with so we have somewhat solid definitions:
- Data: You’ve got to have data to create a machine learning model.
- Preprocess: This step, which could be part of the preceding data step, is essentially about formatting the data in a way that it works for the ensuing steps. Do you need flat file data to be in a CSV file before it goes into the next step? Then you have to figure out a way to, “Preprocess,” it, it’s as simple as that.
- Train: Models must be trained to be able to make predictions. There are lots of ways to train models, but mostly it’s using some type of Python-based package such as Scikit Learn or Tensorflow.
- Evaluate: Just as a teacher has to grade students’ tests, models must be evaluated. This may range from scoring a model for performance against a benchmark, or having a human look at things and take notes to ensure that things are not overfit and therefore useless even though they perform well. Evaluation is the combination of human and machine measurement of models.
- Deploy: Once a model is good enough to go and be used, presumably by a customer or stakeholder, it’s ready to go into production, where it has to be formatted to an API endpoint of some kind and ultimately connected to a front end app so it can be invoked. Back to the, “button press to invoke a simple model,” analogy mentioned above - the user has to be able to press a button, and then that button connects to a function which then, assuming everything is formatted properly, has to run an, “Inference,” on a pre-built model. That pre-build model is sitting there ready for use until that button is pressed.
This is the type of architecture that at the time of writing this article, Linkedin and Spotify show on their website - not going into too much detail, but showing the general overview.
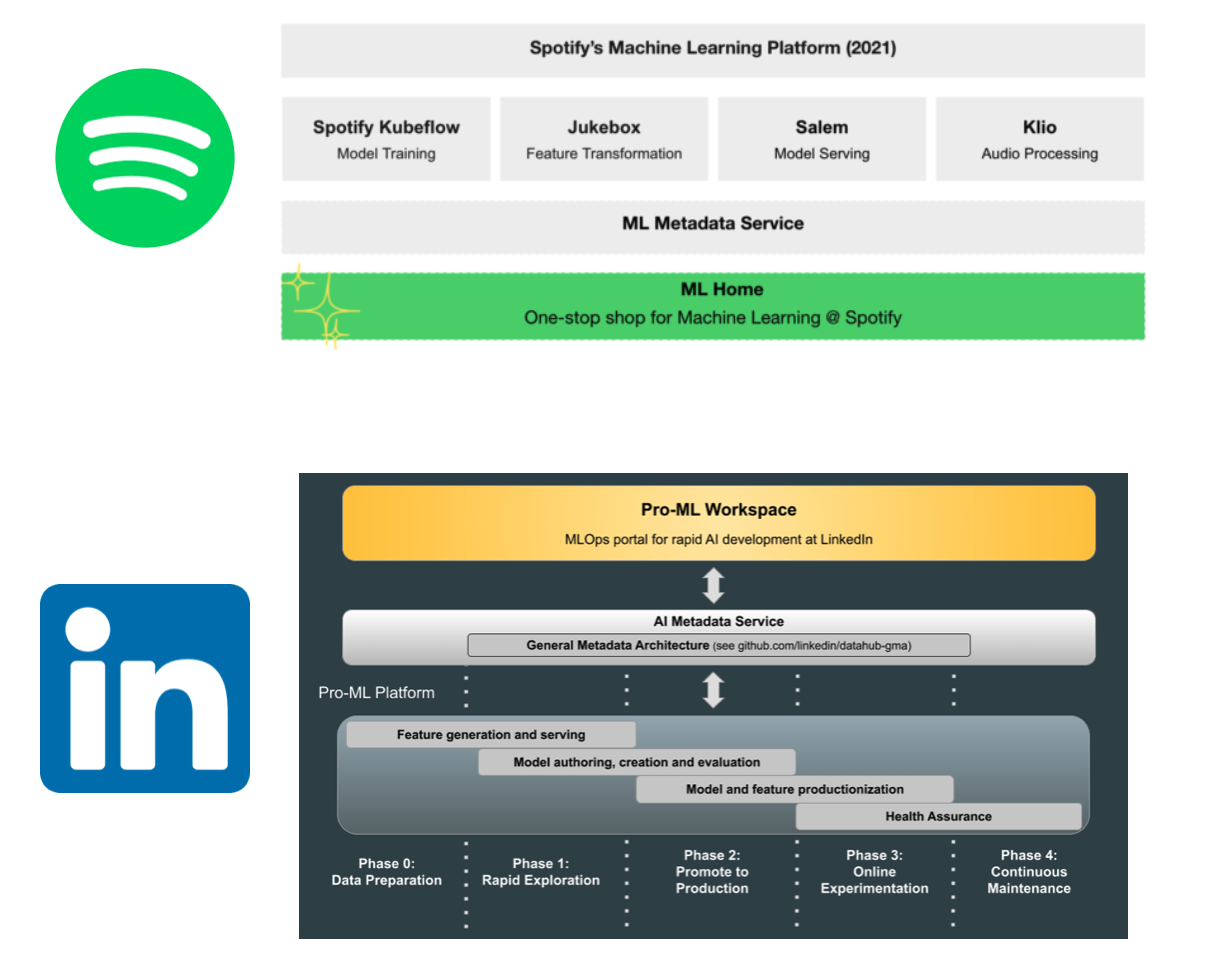
| Source |
|---|
| LinkedIn Engineering Blog |
| Spotify Engineering Blog |
Going into a bit more detail, we might pull apart our architecture a bit more and separate some of the concepts within each step so we can have more of a road map of what’s going on:
The Daedalus Dataflow
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> {load_data; clean_data; split_data;} -> preprocess
preprocess -> {feature_engineering; feature_selection;} -> train
train -> {model_selection; hyperparameter_tuning;} -> evaluate
evaluate -> {performance_metrics; model_comparison;} -> deploy;
}
In Greek Mythology, Daedalus was a skilled craftsman and inventor who created the famous labyrinth on the island of Crete. In contrast the the Persephone Protocol, which is more representative of the changing flow of the seasons, the Daedalus Dataflow is more labyrinthian and complex. However it’s still an abstraction and we haven’t actually talked about any actual software yet.
Preprocessing may have multiple steps involving different types of loading, cleaning or splitting. The output of preprocessing might be something called a, “feature,” which is essentially a column of a field of data, which may or may not need to be saved and shared with other data scientists throughout the discovery process in order to build better models. After training is done, models might be selected, or there may be some kind of auto-model discovery process which involves the use of hyperparameters to have a machine run through a wide variety of models automatically on behalf of the data scientist. Finally, there’s the process of picking and measuring against performance metrics and also comparing models against one another before we go back into our deployent.
This is the level of detail we get from Doordash, Lyft, Instacart and Monzo. Of course these are companies with thousands of employees, whereas many of us may work for startups or companies with tens or hundreds of employees so many of their specific architecture decisions may not work for us.
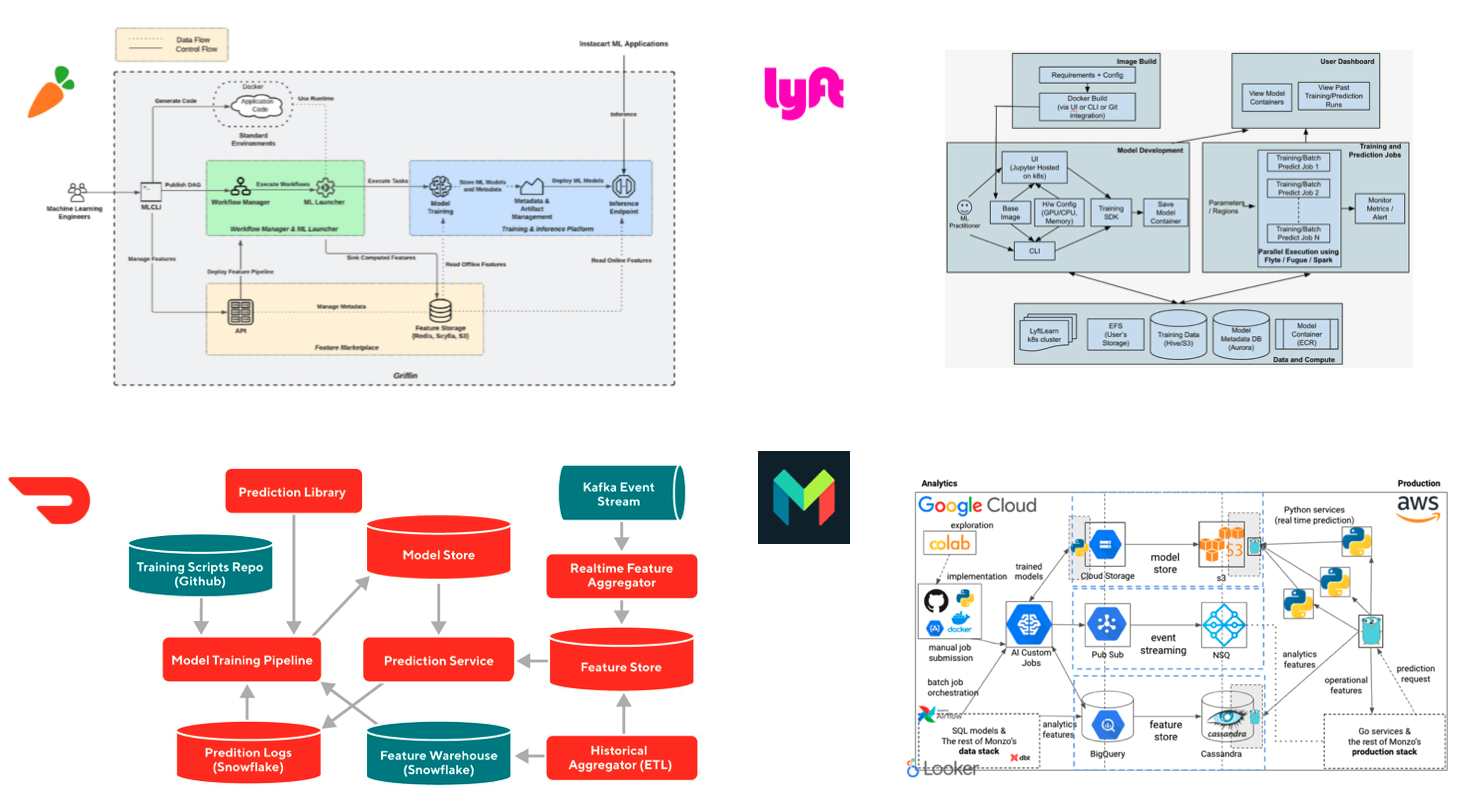
| Source |
|---|
| DoorDash Engineering Blog |
| Lyft Engineering Blog |
| Instacart Engineering Blog |
| Monzo Engineering Blog |
The Prometheus Pipeline
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> Airflow -> {feature_engineering; feature_selection;} -> train;
train -> {model_selection; hyperparameter_tuning;} -> evaluate;
evaluate -> {performance_metrics; model_comparison;} -> deploy;
subgraph cluster_Airflow {
label = "Airflow";
Airflow;
load_data -> preprocess;
clean_data -> preprocess;
split_data -> preprocess;
}
}
So the first component we might look at, purely because it’s on the left hand of the graph and for no other reason, might be something as simple as an Exchange Transform and Load (ETL) or data scheduling platform such as Airflow which might be used to clean the data. However, the data scientists within a particular team may not be that far along and they might clean the data themselves across csv’s or spreadsheets at this point, manually copying and pasting things. That’s not much of a platform, but - there might be other bottlenecks across our entire platform that could be identified by an organization which might be better to focus one’s time on. Again - we’re purely following the diagram from left to right, not necessarily because it makes the most sense across all situations.
Airflow is just one example of a potential solution that could be used. There are multiple different open-source platforms out there. The author went ahead and compared the Github star history of a few interesting ones to each other.
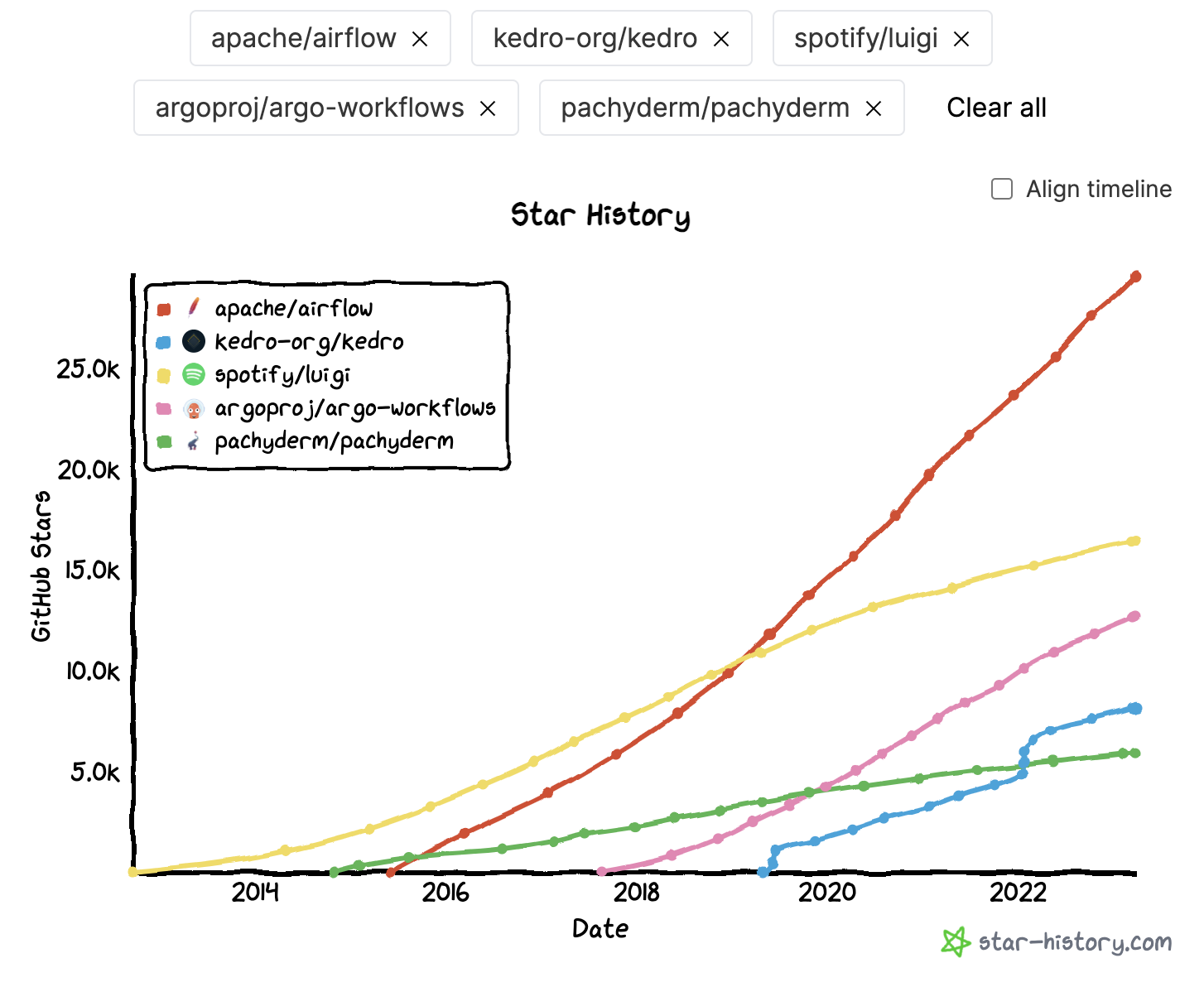
The Zeus Zonal
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> Airflow -> Jupyter
subgraph cluster_Airflow {
label = "Airflow";
Airflow;
load_data -> preprocess;
clean_data -> preprocess;
split_data -> preprocess;
}
subgraph cluster_Jupyter {
label = "Jupyter Notebook Container";
{feature_engineering; feature_selection;} -> train;
train -> model_selection
evaluate
Jupyter
}
Jupyter -> {hyperparameter_tuning;};
{model_selection; hyperparameter_tuning;} -> evaluate;
evaluate -> deploy
}
The naming here is a bit of a cheat, as Zeus is the Greek name for the Roman God Jupyter. Zeus is extremely powerful, much like Jupyter Notebooks, it’s the center point of the Machine Learning and Artificial Intelligence development workflow for many.
Jupyter can run the whole gambit from feature engineering, training, feature selection, model selection and evaluation. Typically this workflow is all done within Jupyter Notebooks by the vast majority of data scientists out there. At the end of the data, data scientists just need some type of Jupyter-Notebook-like environment to work with typically, and it’s going to be an Interactive Development Environment (IDE) because a lot of the most talented data scientists out there didn’t necessarily come from a hard coding or DevOps background, they spent the majority of their time being interested in purely the data science and just doing what it takes to get that stuff done. So if you’re tasked with building the actual data science pipeline, you have to keep those, “human factors considerations,” in mind, but for the purposes of this article, we’re going to assume that 99% of who is out there in terms of data scientists are most familiar with the Jupyter Notebook environment.
That being said, up in our Daedalus Dataflow section you can see within the Mondo blog that they do in fact use Google Colab, not Jupyter Notebooks, so Jupyter is not the only option.
Nemesis Normalization
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> Airflow -> Jupyter
subgraph cluster_Airflow {
label = "Airflow";
Airflow;
load_data -> preprocess;
clean_data -> preprocess;
split_data -> preprocess;
}
subgraph cluster_Jupyter {
label = "Jupyter Notebook Container";
subgraph cluster_ModelSelection {
label = "Model Selection";
model_selection -> S3;
S3 [shape=cylinder]
}
{feature_engineering; feature_selection;} -> train;
train -> model_selection
evaluate
quick_preprocessing -> Jupyter
Jupyter
}
Jupyter -> {hyperparameter_tuning;};
{model_selection; hyperparameter_tuning;} -> evaluate;
evaluate -> deploy
}
Moving along, we move into the actual process of Model Selection, but also Model Storage. In Greek mythology, Nemesis was the goddess of divine retribution and revenge, often depicted as an avenger who punished those who were guilty of hubris or arrogance. When we get into the, “model selection,” portion of the pipeline, we are helping to ensure models are accurate and effective in their predictions, as opposed to being arrogant and non-effective.
So once a data scientist finishes their process of training and evaluation, they likely need a place to store the models so that they can be later accessed. One potential solution which could get quite messy, but could be workable to start off with for prototyping, is to simply use AWS S3 or equivalent, and to have an agreed upon convention for storing models at particular prefixes. The question of storing models then could be as trivial as just agreeing upon a convention for S3 prefixes and using a boto3 client, perhaps even a home-rolled Python package as a wrapper around this client to help keep things structured.
The Odysseus Orchestration
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> Airflow -> Jupyter
subgraph cluster_Airflow {
label = "Airflow";
Airflow;
load_data -> preprocess;
clean_data -> preprocess;
split_data -> preprocess;
}
subgraph cluster_Jupyter {
label = "Jupyter Notebook Container";
subgraph cluster_ModelSelection {
label = "Data Version Control";
model_selection -> S3 [shape=cylinder];
}
{feature_engineering; feature_selection;} -> train;
train -> model_selection
evaluate
quick_preprocessing -> Jupyter
Jupyter
}
Jupyter -> {hyperparameter_tuning;};
{model_selection; hyperparameter_tuning;} -> evaluate;
S3 [shape=cylinder]
evaluate -> S3
subgraph cluster_Server {
label = "Server";
S3 -> deploy;
}
}
Odysseus, in Greek Mythology was basically a guy who got lost and had to take a long and winding path to get back home with many challenges along the way.
Long Term Importance of Odysseus Orchestration
I think the challenge of model selection and data versioning was put best bythe 2016 Blog Post by S. Zayd Enam, Why is machine learning ‘hard’?
What is unique about machine learning is that it is ‘exponentially’ harder to figure out what is wrong when things don’t work as expected. Compounding this debugging difficulty, there is often a delay in debugging cycles between implementing a fix or upgrade and seeing the result. Very rarely does an algorithm work the first time and so this ends up being where the majority of time is spent in building algorithms.
As the question of keeping track of a myriad of models becomes more complex, and as the organization demands the use case further, one might consider something such as DVC to help keep track of all of the models out there, particularly those in production so that custom service problems can be diagnosed, but also perhaps on the training and evaluation side, which is not shown in this graph. We’re showing more of the bare minimum next step above. Here is the Github star history of a couple different (of what the author understands to be) open source data or model versioning platforms.
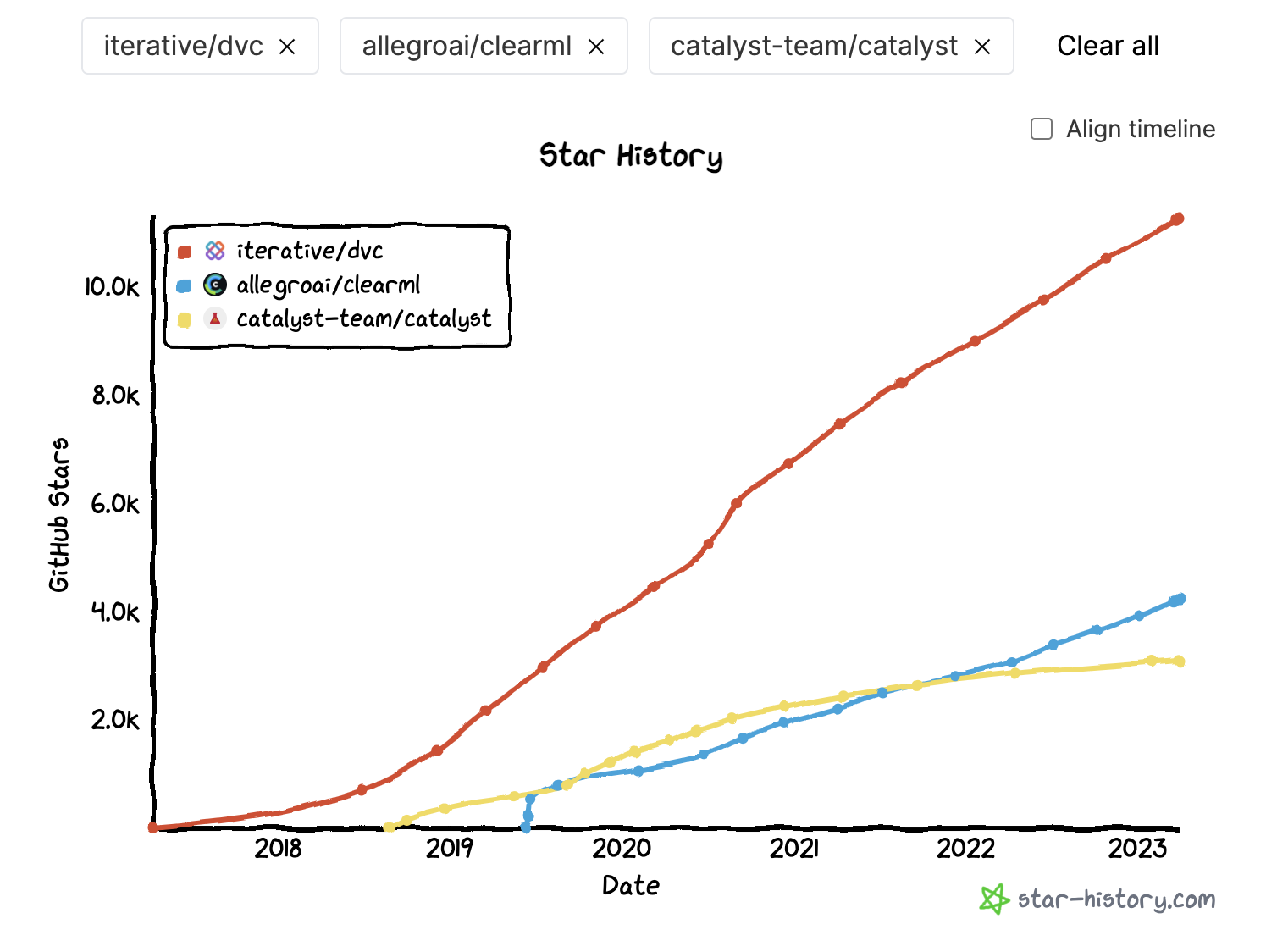
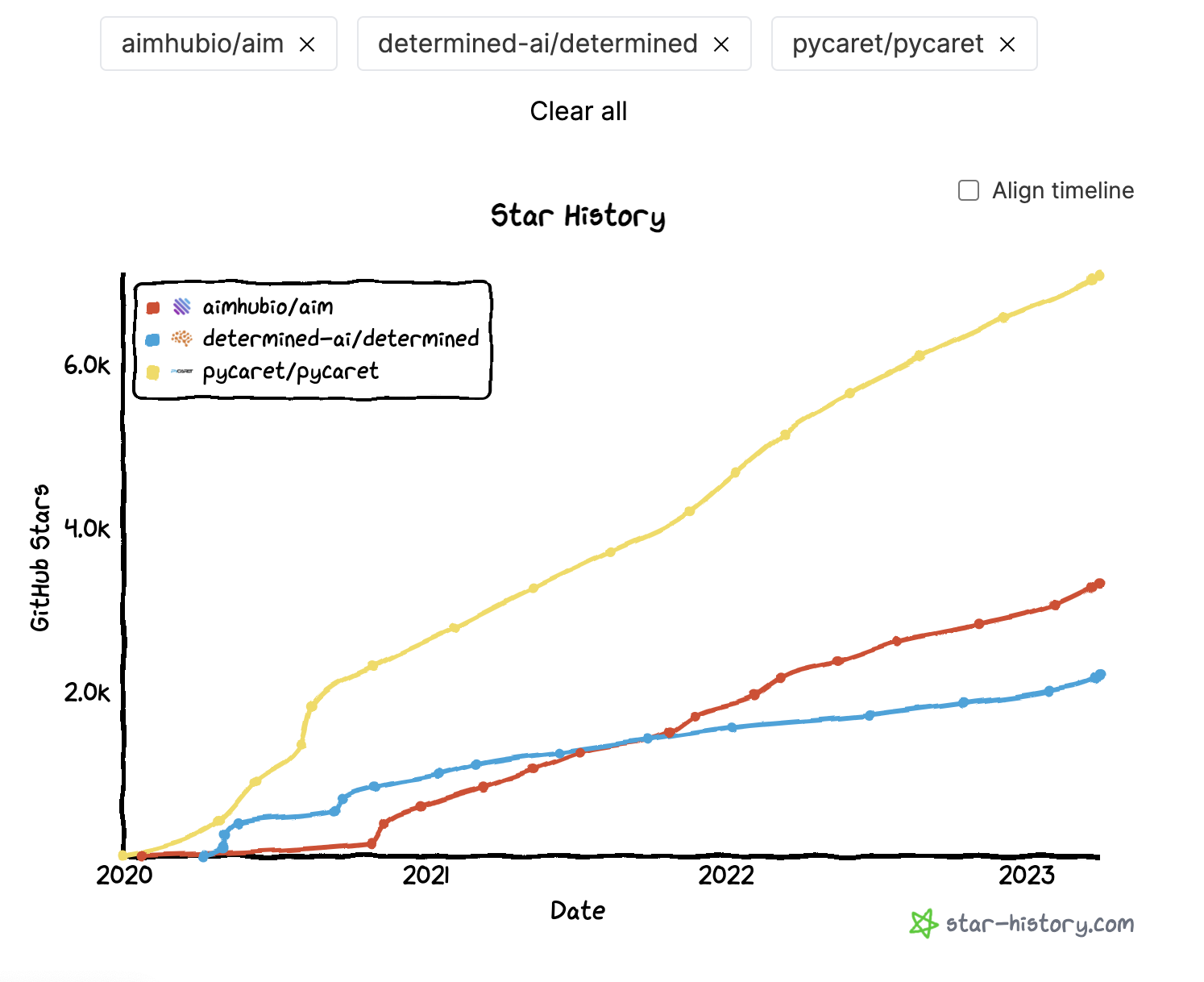
An alternative way of structuring this, might be to use something called Pycaret, installed on your Jupyter Notebook Container, which is really more of a full-service wrapper tool for a lot of the data science functions we have discussed already, and is designed to fit right into Python. However, there are limitations, in that it’s not really designed to work with Tensorflow and more fancy Neural Network stuff, but rather it’s designed to be more of a, “Citizen Data Scientist,” platform which can conceivably be used for prototyping as well.
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> Airflow -> Jupyter
subgraph cluster_Airflow {
label = "Airflow";
Airflow;
load_data -> preprocess;
clean_data -> preprocess;
split_data -> preprocess;
}
subgraph cluster_Jupyter {
label = "Jupyter Notebook Container";
subgraph cluster_Pycaret {
label = "Pycaret";
{feature_engineering; feature_selection;} -> train;
train -> model_selection
model_selection -> S3 [shape=cylinder];
}
quick_preprocessing -> Jupyter
Jupyter
evaluate
}
Jupyter -> {hyperparameter_tuning;};
{model_selection; hyperparameter_tuning;} -> evaluate;
subgraph cluster_Server {
label = "Server";
S3 [shape=cylinder]
S3 -> deploy;
}
}
Below are some potential alternatives to Pycaret with another Github star history comparison.
{kind=link}
Epimetheus Endpoint
digraph ml_workflow {
rankdir=LR;
node [shape=box];
data -> Airflow -> Jupyter
subgraph cluster_Airflow {
label = "Airflow";
Airflow;
load_data -> preprocess;
clean_data -> preprocess;
split_data -> preprocess;
}
subgraph cluster_Jupyter {
label = "Jupyter Notebook Container";
subgraph cluster_Pycaret {
label = "Pycaret";
{feature_engineering; feature_selection;} -> train;
train -> model_selection
model_selection -> S3 [shape=cylinder];
}
quick_preprocessing -> Jupyter
Jupyter
evaluate
}
Jupyter -> {hyperparameter_tuning;};
{model_selection; hyperparameter_tuning;} -> evaluate;
subgraph cluster_Server {
label = "KServe";
S3 [shape=cylinder]
S3 -> deploy;
}
deploy -> frontend_application
}
Next, moving on into deployment. Epimetheus was the lesser known brother of Prometheus, the Titan who brought Fire and enlightenment to humankind. Whereas Prometheus represents foresight, Epimetheus represents hindsight. In a way, in order to deploy a Machine Learning or Artificial Intelligence Model, you have to already have the hindsight of having learned something in order to create a model that is ready to deploy - hence, Epimetheus Endpoint.
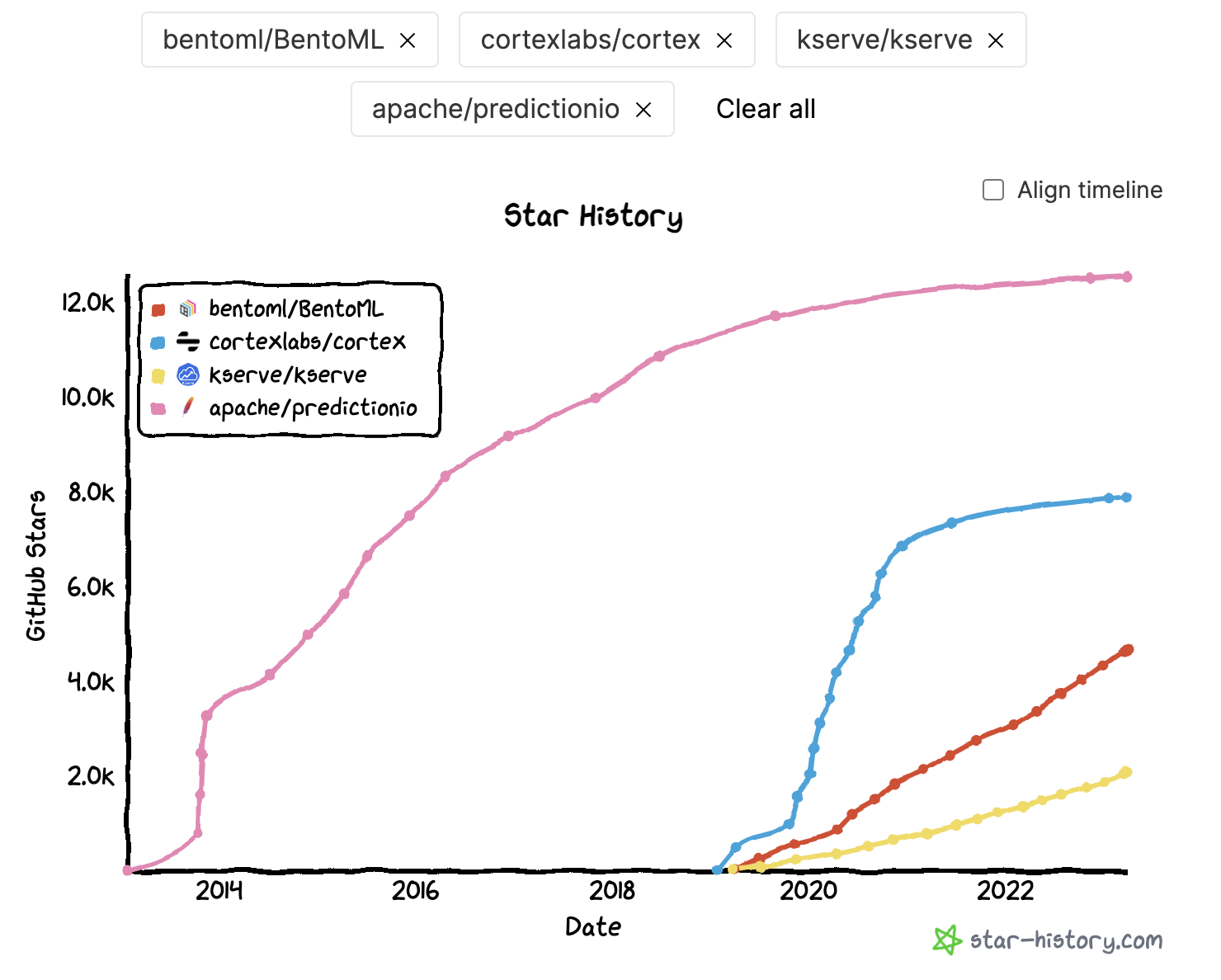
We have the option of either spinning up our own server, such as perhaps a CherryPy or Flask server, which exposes a function endpoint for a particular machine learning model right in the server code itself, or using something such as KServe which is an open source platform that is designed to dynamically store and serve models to endpoints at will. So in other words, if you had a few number of models you were testing at a few number of endpoints, you might just want to build a CherryPy server for those models and try to maintain those, but if you are working with a lot of complex models, switching them out on the fly, you might use a Kserve or other similar application. Below are some additional model serving platforms with Github star history.
Building an Endpoint From Scratch
To help demonstate the importance of the Odysseus Orchestration, it’s important to go through a simple use case of serving an inference model and then inputing a payload into the server’s API to show how it can become complicated quickly when building completely from scratch.
Open source models aside, if one wanted to create a super simple webservice that works to deploy software, one could do so with CherryPy like so:
First a joblib file is required, which would have been created upstream within the The Zeus Zonal portion of the architecture. This also may have been a .pkl file, .pickle, TF2 SavedModel, or any other variety of model - some sort of model. The below assumes that we have the model saved locally within a container.
import joblib
model = joblib.load("path/to/your/model.joblib")
We then serve the model file on an endpoint, perhaps a /predict endpoint that expects a JSON payload in the request body That endpoint can be tested with a curl command after the web service has been started, using the following, assuming it’s serving at localhost:8080:
curl -X POST -H "Content-Type: application/json" \
-d '{"payload": [{"robot-age": 5, "rust-level": "9", "battery": "low"}]}' \
http://localhost:8080/predict
This json payload would hit a prediction function sitting on the server.
def predict():
json_ = request.json
prediction = model.predict(query)
return jsonify({'prediction': list(prediction)})
Which then gives an output, such as:
{"prediction": [0]}
This prediction output can then be used elsewhere in an application, perhaps to display an alert on a website showing that a robot is in, “Bad Condition,” with a binary classification being used behind the scenes.
So this brings up a few points:
More trivially, but still important, dimensional problems:
- What are the input dimensions?
- What are the output prediction dimensions expected given a particular inference?
These are a problem when building an ML server from scratch, because a sufficiently robust prediction function must be built to deal with different scenarios, but not as much of a probem as more model performance oriented problems.
Less trivial model performance oriented problems:
- What version of model was used at model.pkg at what time?
- When was the model released?
- What training data was used to build the model?
- What user reported what feedback about the model at what time, so that the model can be improved?
So while the easiest possible iteration of our Pipeline Abstractions may seem to be to simply build an Epimetheus Endpoint without an Odysseus’ Orchestration, this may present serious performance measurement problems down the line, which could potentially stymie further decision-making. Of course it’s all business case and situation dependant, but this hopefully demonstrates further that Orchestration is a real concern.
Hephaestus Hold
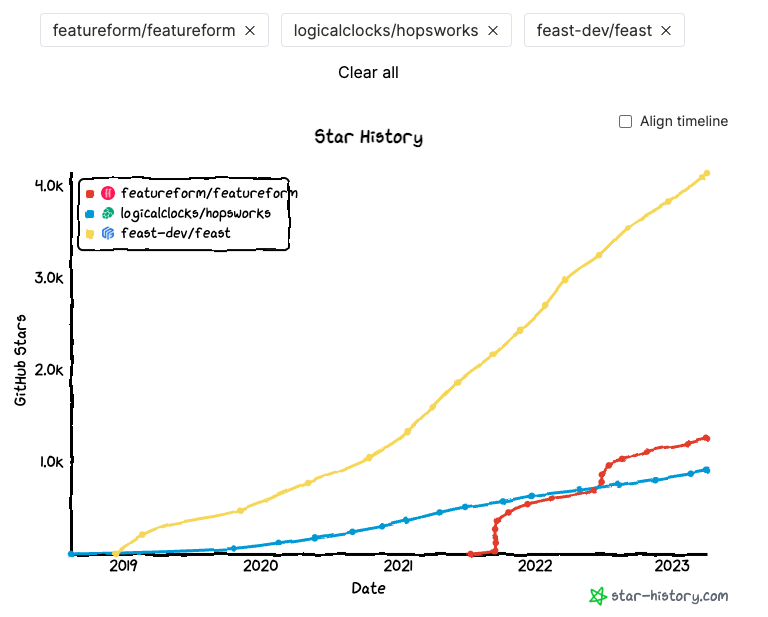
Feature Storage may be something that is needed for more advanced, multi-person teams working with a lot of data that needs to be converted into, “features,” which are basically shareable columns of data that can be used to much more quickly compare models in a collaborative environment, vs. purely sharing just spreadsheets. In Greek mythology, Hephaestus was the god of technology and blacksmiths, known for creating intricate and highly precise mechanical devices. The feature storage component of our architecture may be best represented by Hephaestus.
For an architecture diagram representing feature storage, simply put a box around the two feature storage features and label it with the desired software platform. As for the popularity of different open source platforms go, here’s a quick analysis:
Kubeflow Kraken
Kubeflow is the Kraken because of the alliteration, but also because it is of enormous size and is a potential killer. Now, while the Kraken is beautiful and has many appendages that can multitask and be an everything-at-once platform that does everything we have described above and more, with all sorts of custom resources (plugins) that can be used to expand and customize it - it may also be useful for data science teams that are actually larger in size and may need the type of coordination that it can help build.
Kubeflow is essentially a collection of other open-source tools, including Jupyter Notebooks, centralized by a dashboard feature, and connected together by webhooks.
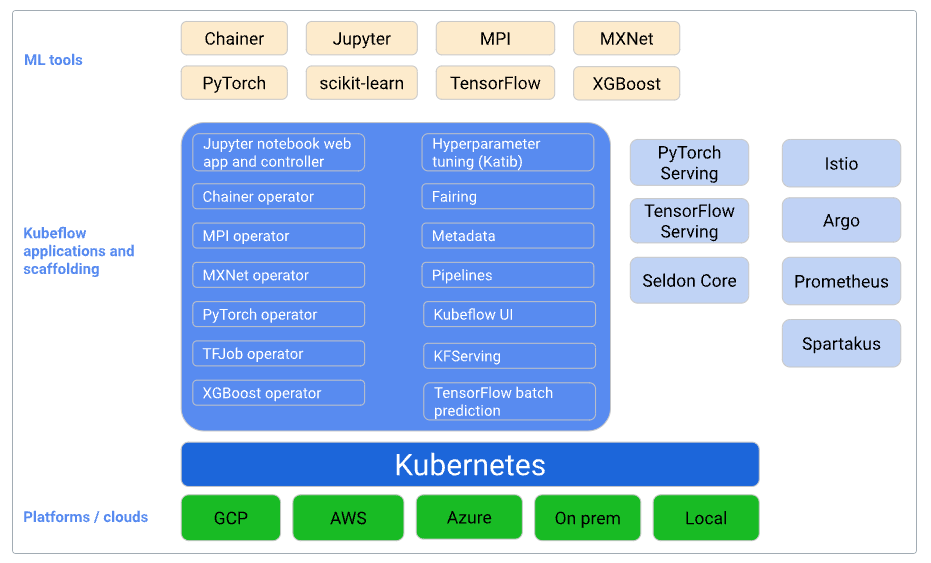
In other words, Kubeflow is really meant for teams, and it’s really complicated to set up. Much of what constitutes Kubeflow is actually just the infrastructure in order to run Kubeflow. That may be fine for what your company is trying to build if it can be properly planned and isolated. However, much like how AWS or various cloud services can get really complicated the more services one uses, requiring more configuration and labor to maintain it, Kubeflow has the same potential scaling problem.
Don’t get me wrong, Kubeflow is a great tool - but the decision to go with Kubeflow should be weighted against where one is at within the AI/ML journey. If you’re a small startup with just yourself or one data scientist, even if you really feel like you need the best thing that’s out there, you probably can get by with a much simpler implementation such as the The Zeus Zonal.
Presumably, Kubeflow’s competitor, MLFlow, has similar challenges, but the author has not personally used it yet.
Rough Breakdown of Kubeflow
What Kubeflow includes, roughly stated:
Data Science Components
-
KServe: Kserve is a way to store different types of exported models depending on the runtime, and it provides a default version of Single Model Serving, but there is also an alpha version of ModelMesh or Multi Model Serving. KServe InferenceServices are essentially a pod with two containers, an actual kserve_container, and a proxy_query.
-
Kubeflow Pipelines: Kubeflow Pipelines is a platform for building and deploying machine learning workflows. This may include cleaning and modifying data and is analogous to an ETL pipeline for machine learning.
-
Katib: Katib is a platform for hyperparameter tuning and neural architecture search.
-
Training Operator: Training Operator is a platform for running distributed machine learning training jobs.
-
Seldon: Seldon is a platform for deploying and managing machine learning models in production. Note, we did not use this component.
Performance Components
- Tensorboard: Tensorboard provides a way to visualize machine learning models and their performance.
Usability Components
-
Kubeflow Namespace: The Kubeflow Namespace is a way to isolate Kubeflow applications from other applications running in Kubernetes.
-
Kubeflow Roles: Kubeflow Roles allow for fine-grained access control to resources in Kubeflow.
-
Multi-User Kubeflow Pipelines: Multi-User Kubeflow Pipelines allow for multiple users to collaborate on a single pipeline.
-
Central Dashboard: The Central Dashboard is the starting place for data scientists to log in and access Jupyter Notebooks and other tools.
-
Notebooks: Jupyter Notebooks are integrated into the Central Dashboard and provide a way to interactively explore data, build and train models, and share results.
-
User Namespace: The User Namespace is a way to isolate users and their resources from other users in Kubeflow.
Networking, Cert, Auth, Integration with Kubernetes
-
Cert Manager: Cert Manager provides certificates for admission webhooks, which is a way to ensure that the central dashboard UI and other tools are not spoofed.
-
Istio: Istio abstracts traffic routing out of the applications that make up Kubeflow, allowing for traffic routing features without needing to inject code into the existing Kubernetes applications.
-
OIDC Auth Service: OIDC Auth Service uses OpenID Connect to drive authentication for other applications.
-
Dex: Dex acts as a portal to other identity providers through connectors. Clients write their authentication logic once to talk to dex, then dex handles the protocols for a given backend.
-
Knative Serving: Knative Serving helps define a set of CRD’s, which control how the workload behaves on the cluster.
-
Admission Webhook Deployment: Admission Webhook Deployment is a way to ensure that all incoming requests are authenticated before they are allowed to access Kubeflow applications.
-
Profiles and Kubeflow Access Management (KFAM): Profiles and Kubeflow Access Management (KFAM) provide a way to manage user access to Kubeflow resources.
-
Volumes: Volumes provide a way to store data that is needed by Kubeflow applications.
Closing Up
So reviewing what we have covered in this article:
- Looking at ML/AI workflow pipelines can help with planning and conversations about what is needed at what time.
- Business and organizational need timeframes change, so being able to adapt is a good thing.
- There are ways to build a ML/AI workflow platform or parts of ML/AI workflow platforms from scratch, and there are various open source tools that can be stiched together at different points in time, depending upon the unique challenges at the time.
We’ve stayed away from any specific recommendation here, but rather built a map, much like ancient Greek sailors within mythology often would benefit from having maps to help them navigate the mysterious and daunting world of demigods and monsters.
Appendix, Further Assumptions, Prerequisites
- Docker assumed.
- This article skips over the build-vs-buy conversation completely. The assumption here is that a platform will be built, not bought.
- We’re abstracting away infrastructure and networking concerns in this article. Notably, GPU’s are far more expensive than CPU’s for the purposes of training, so a large challenge which is not described within the Zeus Zonal section is being able to potentially control access to training resources. This may also become a factor for inference resources if the endpoint demands something super fast. We’re not paying attention to any of that in this article and we’re assuming infrastructure is easy, which it is not…but it would require its own article to cover.
- Security is also a thing. It’s very important to remember not to screw this up! Kidding aside - don’t use build arguments because tokens can show up in logs. Mount your tokens and secrets, don’t put them anywhere in the Git repo. There are too many security considerations to cover but these are two that have bit the author.
- Databases are also a thing. We didn’t really cover databases here and assumed that these are more trivial, or at least there is a lot more common knowledge on how to integrate databases. Obviously they are not trivial either, but it’s just less of a, “newer,” topic to a lot of folks at the time of authoring this post.
- We didn’t cover automl or hyperparameters, but this is an extended feature which could presumably be tied into a Jupyter notebook.
- We used Github stars as a metric for quality and did not include any repos which had exponential jumps in Github stars due to the potential risk of those stars being purchased. This signal might not disqualify a repo outright, but our assumption here is that anyone who may potentially have bought stars (which may not be true), is a risk, because if they are willing to commit shennanigans in one area, they may be willing to commit shennanigans in another. Granted, it may be possible that star jumps were in fact organic, we were just overly-conservative in not sharing anything that even looks like potential Github star purchasing.